

در تحليلهاى آمار استنباطى همواره نظر بر اين است که نتايج حاصل از مطالعه گروه کوچکى به نام نمونه چگونه به گروه بزرگترى به نام جامعه تعميم داده شود. در اين قسمت مباحثى چون همبستگى و تست مورد بررسى و اشاره قرار مىگيرد.
همبستگى
رابطه همبستگى به بررسى ارتباط بين دو يا چند متغير مىپردازد و ضريب آن را محاسبه مىنمايد. همبستگى بين متغيرها ممکن است مثبت يا منفى باشد. اگر تغييرات يک متغير با تغييرات متغير ديگر همراه باشد و افزايش يکى با افزايش ديگرى يا بالعکس کاهش يکى با کاهش ديگرى همراه بشود، مىگوييم که همبستگى بين آنها مثبت است؛ مانند افزايش درآمد و افزايش تقاضا براى خريد. همبستگى مثبت از ۰ تا ۱+ نوسان دارد، يعنى همبستگى کامل مثبت از ضريب ۱+ برخوردار است.
اگر تغيير و افزايش يک متغير با کاهش متغير ديگرى همراه شود، گفته مىشود که همبستگى بين آنها منفى است و مقدار آن از ۰ تا ۱- تغيير مىکند، يعنى ميزان همبستگى کامل منفى برابر ۱- است. اگر بين دو متغير رابطهاى وجود نداشته باشد، ضريب همبستگى صفر خواهد بود. نحوه و ميزان همبستگى متغيرها را مىتوان در دستگاه مختصات مانند طرح ذيل نمايش داد.
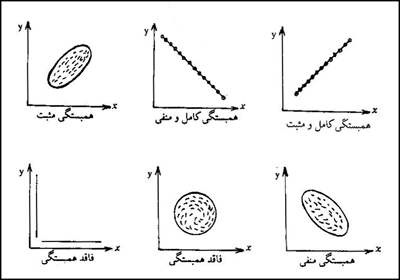
انواع همبستگىها. براى محاسبه همبستگى بين متغيرها بايد محقق مقياس اندازهگيرى را ملاحظه نمايد؛ زيرا با توجه به مقياسهاى اندازهگيرى که قبلاً ذکر شد، نوع روش بررسى و محاسبه همبستگى متفاوت است؛ يعنى هر يک از مقياسهاى اسمي، رتبهاي، نسبى و فاصلهاى روش محاسبهٔ همبستگى خاص خود را دارند و محقق بايد از فرمول و روش مربوط به آن استفاده کند:
- آزمون همبستگى پيرسون (Pearson). اين آزمون يکى از متداولترين آزمونهاى تعيين ضريب همبستگى بين متغيرهاى داراى اندازههاى فاصلهاى و نسبى است و براى محاسبه ضريب آن از فرمول زير استفاده مىشود: (نادري، عزتالله و مريم سيف نراقي؛ آمار استنباطى در علوم انساني؛ ص ۲۸.)
| ∑ x y | |||
| = | rx,y | ||
| N Sx Sy |
در اين فرمول rx,y، همبستگى بين متغيرهاى N y ،x، تعداد آزمودنىها؛ Sx ، انحراف استاندارد نمرههاى x؛ xy∑، مجموع حاصلضرب تفاضل نمرهها از ميانگين و Sy ، انحراف استاندارد نمرههاى y است.
براى محاسبه ضريب همبستگى پيرسون فرمولهاى ديگرى نظير دو فرمول زير نيز وجود دارد که براى اطلاع بيشتر مىتوان به کتب آمار مراجعه نمود.
| ∑ (x - x̄)(y - ȳ) | ||||
| = | rx,y | |||
| ∑(x - x̄)۲(y - ȳ)۲ | √ | |||
يا
| ∑ x y | ||||
| = | rx,y | |||
| ∑ ( x۲ ) ( y۲ ) | √ | |||
پس از محاسبهٔ ضريب همبستگى محقق بايد معنادار بودن يا نبودن آن را مورد بررسى قرار دهد. براى اين کار ابتدا لازم است درجهٔ آزادى از فرمول df=N-۲ محاسبه شود. (N معادل آزمودنىهاست). سپس با در نظر گرفتن درجه آزادى و سطح احتمال موردنظر (۱% يا ۵% خطا)، محقق ضريب همبستگى محاسبه شده را با ميزان محاسبه شده در جدول مربوط مقايسه مىکند. چنانچه ضريب محاسبهشده مساوى يا بزرگتر از عدد جدول باشد، ضريب همبستگى معنادار است و وجود همبستگى بين متغيرها را تأييد مىکند؛ ولى اگر مقدار محاسبه شده از مقدار جدول کمتر باشد، نمىتواند وجود ضريب همبستگى را بپذيرد.
- آزمون رو (Rho) يا ضريب همبستگى اسپيرمن (Spearman) . اين آزمون زمانى بکار مىرود که دادهها از نوع رتبهاى است و اندازههاى متغيرها بصورت رتبهاى تنظيم شده است؛ مانند رتبهبندى دانشآموزان يک کلاس در نمرهٔ رياضى يا نمرهٔ فيزيک. براى محاسبهٔ ضريب همبستگى از فرمول زير استفاده مىشود: (نادري، عزتالله و مريم سيف نراقي؛ آمار استنباطى در علوم انساني؛ ص ۳۳)
| ۶ ∑ D۲ | ||||
| ۱ - | = | Rrho | ||
| N ( N۲ - ۱ ) |
در اين فرمول D، تفاضل رتبهٔ x از y (تفاضل رتبهٔ نمره رياضى از رتبهٔ نمرهٔ فيزيک) و N، تعداد جفت آزمودنىهاست.
در اين روش نيز محقق بايد ضمن محاسبهٔ درجهٔ آزادى و با انتخاب سطح احتمال موردنظر (1% يا ۵%) به جدول معنىدارى ضريب همبستگى اسپيرمن مراجعه کند و ضريب همبستگى محاسبه شده را با آن مقايسه کند. در صورتىکه عدد آن مساوى يا بزرگتر از عدد جدول بود ضريب همبستگى معنادار است و همبستگى و ميزان آن تأييد و فرضيه صفر رد مىشود.
- آزمون يا ضريب همبستگى فاى (). از اين آزمون براى محاسبهٔ ضريب همبستگى بين متغيرها و دادههايى استفاده مىشود که از نوع اسمى يا کيفى و ارزشى هستند. براى محاسبهٔ ضريب همبستگى فاى ابتدا جدول دوبعدى تشکيل داده مىشود، سپس آزمون خى ۲ (X۲) يا مجذور کا يا کاى اسکوئر (Chi-Square) محاسبه مىشود. مجذور کا ميزان احتمال تصادفى و شانسى بودن همبستگى بين دو يا چند متغير يا دو يا چند ارزش را نيز تعيين مىنمايد. پس از محاسبه مجذور کا مىتوان ضريب همبستگى فاى را محاسبه کرد. (نادري، عزتالله و مريم سيف نراقي؛ آمار استنباطى در علوم انساني؛ ص ۳۴)
آزمون خى ۲ داراى محدوديتهايى بشرح زير است:
۱. تنها در مورد اطلاعات مربوط به فراوانى مىتواند مورد استفاده قرار گيرد و نه در مورد نمرهها.
۲. بايد رويدادها و اندازهگيرىهاى فردى از يکديگر مستقل باشند؛ يعنى اطلاعات، پيوسته نباشند و بصورت گسسته و طبقهاى وجود داشته باشند و اساساً اين آزمون غيرپارامتريک است.
۳. بطورکلى هيچ فراوانى مورد انتظار نبايد از ۵ کمتر باشد، مگر تحت شرايط خاص و آن اينکه از تصحيح استفاده شود.
براى محاسبه خى ۲ از فرمول X ۲=∑(Fo-Fe)۲/Fe و براى محاسبه خى ۲ با تصحيح ييتس از فرمول ( X۲=∑ ( (|Fo-Fe|-./۵)۲/Fe استفاده مىشود. (نادري، عزتالله و مريم سيف نراقي؛ آمار استنباطى در علوم انساني؛ ص ۳۶) Fo فراوانى مشاهده شده است که واقعيت دارد و از نتايج دادهها استخراج و در جدول دوبُعدى قرار داده شده است و Fe فراوانى مورد انتظار است.
اگر براى محاسبه و برآورد فراوانى مورد انتظار آزمون مزبور دربارهٔ ارتباط بين ارزشهاى يک متغير باشد، کافى است تعداد رخدادهاى متغير بر تعداد ارزشهاى آن تقسيم شود. بدين ترتيب فراوانىهاى مورد انتظار هر خانه بدست خواهد آمد که با هم برابرند؛ مثلاً اگر از دانشآموزان کلاسى در مورد چهار پيشنهاد بازديد از موزه، رفتن به باغوحش، گردش در پارک و رفتن به کنار دريا در يک گردش دستهجمعى سؤال شود و پاسخ آنها به ترتيب عبارت باشد از: بازديد از موزه ۱۵ نفر، رفتن به باغوحش ۱۵ نفر، گردش در پارک ۳۰ نفر، رفتن به کنار دريا ۴۰ نفر، در چنين حالتى فراوانى مورد انتظار عبارت خواهد بود از:
| ۴۰ + ۳۰ + ۱۵ + ۱۵ | ||
| ۲۵ = | ||
| ۴ |
در اينجا با استفاده از فرمول مزبور، خى ۲ براى هر ارزش محاسبه و از جمع خى ۲هاى چهار ارزش مزبور خى ۲ کل محاسبه خواهد شد و محقق مىتواند با تعيين درجهٔ آزادى و مقايسه خى ۲ محاسبه شده در سطح احتمال موردنظر (۱% يا ۵%) معنىدار بودن يا نبودن تفاوت بين نظرهاى دانشآموزان را مشخص نمايد. براى محاسبه و تعيين درجه آزادى از فرمول ذيل استفاده مىشود:
| ( تعداد سطرها در جدول ) ( ۱- تعداد ستونها در جدول) = d f |
اگر هدف محقق آزمون همبستگى بين دو يا چند متغير باشد، براى محاسبهٔ فراوانى مورد انتظار از مجموع فراوانىهاى سطر و ستون و از فرمول زير استفاده مىنمايد:
| A = جمع فراوانىهاى مشاهده شده در سطر X جمع فراوانىهاى مشاهده شده در ستون | |
| N = جمع فراوانى مشاهده شده | |
| Fe = فراوانى مورد انتظار در خانهٔ موردنظر در جدول | |
| Fe = A / N |
حال اگر بخواهيم ضريب همبستگى فاى را محاسبه کنيم از فرمول = √(X۲) / N استفاده مىکنيم.